机器学习笔记-1-概述
机器学习试图通过机器,帮助人归纳出蕴含在数据中的有价值的信息。 前提是需要人提供知识的形式、分类的形式,基于人提供的信息,机器通过见到的历史数据自动把特征信息学习出来。
机器学习技术和很多领域相关,在很多领域内都能找到成功的应用。最本质的,机器学习是人工智能领域的一个大的分支,也是人工智能领域中最活跃、应用最多的分支。同时,目前的机器学习技术越来越多的是基于统计的方法和思想来展开,所以和统计学的交集也比较大。
1. Why machine learning
1.1 在工业界得到了很大拓展
之所以越来越受到重视,是因为在很多领域,有很多问题用传统方法很难解决。需要人具有很高等的智慧和很大的人力投入,甚至也得不到解决。 这时产生了一些机器学习主义者,这些人在解决实际问题时,不对领域做过多深入的研究,比如机器视觉、语言学。 如果用统计的角度来看这些问题,标一些数据让机器学习一下试试,其实是一种很简单的方法,但是发现在很多领域得到了令人惊讶的不错的结果。 发现用统计学的方法解决实际问题,是一种很有效的,至少是值得尝试的技术。在很多领域都得到了令人满意的结果。
很多标志性事件,显示了人工智能和机器学习具有不可思议的潜力:
围棋:Google的AlphaGo胜过了李世石和柯杰
自然语言
Apple的siri获得了很大的成功;微软的实时翻译准确率得到了突破。
自动摘要、自动写文章等众多应用的成果已经可用。
指纹识别 已经成功运用于门禁、考勤、电脑、手机安全等等。
手指指腹上都有凹凸的皮肤所形成的纹路,这些纹路有许多细节特征,例如起点、终点、结合点和分叉点。每个人的指纹并不相同,指纹识别就是通过比较这些细节特征的区别来进行鉴别。先用海量的指纹对机器进行训练,告诉它什么样的指纹是谁的。然后机器在成千上万次的学习过程中学会了如何提取了指纹的特征值及判断。
自动驾驶技术试验的逐步成功。
Tesla、Google、百度和很多初创企业的自动驾驶,得到法律允许路试,被逐步验证是可行的。
1.2 近两年硬件和软件的发展
GPU Nvidia的CUDA并行计算,使得计算能力得到了提升。
众多机器学习框架的推广。 Caffe、Tensorflow等的推广,使得程序员编写和实验机器学习的难度大大降低。
1.3 互联网数据的积累和处理需求
过去 20 年互联网的高速发展,产生了大量需要被人工智能处理和加工提炼的数据。数据处理的需求一定程度上催生了人工智能的迅猛发展。
1.4 很多方法有比较坚实的理论基础:
作为一门交叉学科,涉及到统计学、人工智能、计算复杂性理论、信息论、控制论、哲学、心理学和神经生物学等。
比较有意思的地方,基于数学基础能帮我们设计构造出很多可用的模型和方法。比如,可以用数学证明出中庸思想、民主相对于独裁的优势、做事加好就收。有很多宝贵的哲学思想可以转换成程序。
2. What is machine learning
机器学习的意义
有些事情人做比较容易,基于规则去编写程序解决这些问题非常繁琐、效果不好。“想到”和“做到”都很难。
比如判断人出行回开车还是走路,可以着眼于天气、衣着、是否工作日等简单的因素,判断是否垃圾邮件,可以依赖一些白名单、黑名单关键词,写一些逻辑判断。但如果达到很高的准确率,可衡量的因子太多了。 但是,人的分析、总结的能力有限,不可能面面俱到,考虑到所有的可能性;把这些因素和逻辑判断,完整的写入到程序,也需要很大的精力。 如果能自动构建一个程序,把这些因素分析出来,这就是一个很直接的机器学习可用的地方。
比如自然语言处理中的文章情感识别,比如人脸识别、人脸朝向。
人类学习的一般步骤
Learning = Imporving with experience
Momorizing -> Learning facts -> Desision Making
Memorizing something
Learning facts through observation and exploration, Organization of new knowledge into general, effective representations
Using the learned knowledge for decision making
学而不思则罔,思而不学则殆
定义:对于某类任务$T$和性能度量$P$,如果一个计算机程序在$T$上以$P$衡量的性能随着经验$E$而自我完善,那么我们称这个计算机程序在从经验$E$中学习。
3. What is the general process
3.1 机器学习解决问题的一般框架
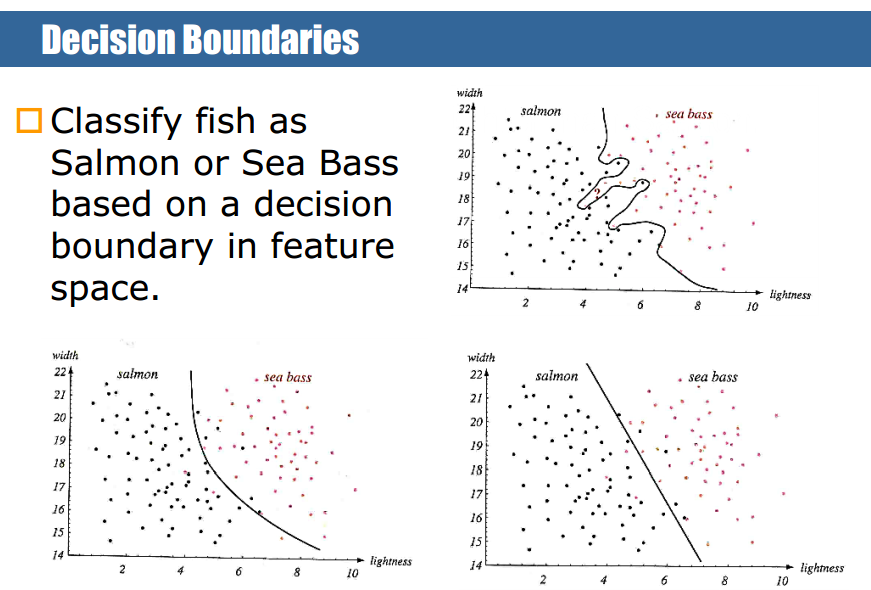
举例:对鱼进行自动分类 。
T:Classify fish
P: % of correct decisions
E: Manual classification
a. 选择Model模型:
表达形式,要学的知识是一种什么形式? What exactly should be learned? How shall it be represented?
-> 在这里是一个
Decision boundary,人指定了长度和亮度两个特征,学习的是二维空间中的一个决策面。Assumptions
Where to find the answer? -> `Boundary set in the <length, lightness> feature space` What can we assume about the answer? -> `Linear boundary or more complex ones`图1:分类面
b. 收集经验 Experience
what “past experience” can we rely on? 怎么收集数据?
-> Historical data: Human classification
(<length, lightness> type)c. Learning
How to automatically improve?
Statistical approach决定学习的算法,基于给定的知识的形式
d. Classifying
How to automatically improve?
relationship between <length,lightness> and the boundary怎么应用学出来的东西
e. Evaluation
How well are we doing? 度量好坏
图2:鱼分类机器学习设计

3.2 机器学习设计的术语化描述
图3:机器学习术语化描述
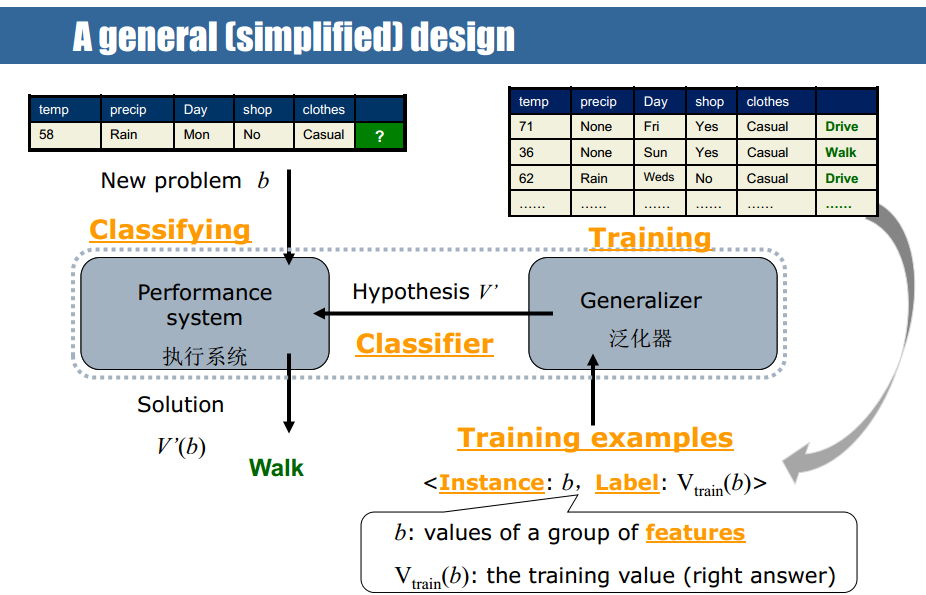
首先收集到一些历史数据 E ,经过人工标注,称为 Training examples 训练样例
Training example 包括两个部分,一部分是能见到的数据属性,被称为 Instance 实例,被标注的数据属性被称为 label 标签
训练样例被放到一个训练 training 过程里,也可称为学习 learning 过程、泛化器 Generalizer 。
训练过程基于训练数据,可以学习出一个分类器 Classifier 。
教材是一种假设空间 Hypothesis 搜索的方式进行,假设空间中有很多候选的假设,比如二维空间中的所有可能的直线的集合,就是一个假设空间。在假设空间中找到一个假设,尽可能的符合训练数据。
在应用过程中,把未知 instance 放到学习出来的分类器里,分类器就可以给新数据打一个分类标签。这个标注过程也称为分类过程。